














mvp2run
August 8th, 2018 Update: Hurricane affinity issues were related to a bug in mvapich2-2.2. Because of this, mvapich2-2.3 is available now on hurricane and whirlwind. Please upgrade to this version on hurricane and whirlwind. Until this can be done, please use '-a' with mvp2run to turn off affinity, this is a workaround to the bug in mvapich2-2.2.
Summary
The command mvp2run is used to simplify the launch of MPI parallel jobs on the SciClone and Chesapeake clusters. The command can also be used to launch OpenMP/MPI hybrid jobs with the addition of some command-line options. The script is able to launch codes compiled with GNU, PGI, and Intel using either MVAPICH2, OpenMPI, and IntelMPI MPI libraries. Here is a list of the command-line options:
mvp2run [-ahvLH] [-c np] [-m vp | cyclic | blocked]
[-C load | -X load]
[-e VAR=value ||-e "VAR value"] ... <program> [<args>]
Description: Run an MVAPICH2/OPENMPI/INTELMPI application under TORQUE.
Options: -a Turn of all mpi affinity
(useful for OpenMP/MPI hybrid).
-c Run "np" copies of the program on the
allocated nodes.
-C Check if node activity exceeds "load".
-e Assign "value" to environment variable VAR.
-h Print this help message.
-H Just generate hosts and rank file and exit.
-m Select process-to-node mapping scheme.
-v Verbose mode.
-X Abort if node activity exceeds "load". Implies -C.
<program> Executable MPI application.
<args> Arguments for application program.
Examples
- General use (-h, -v)
- Passing variables (-e)
- Checking the load (-C -X)
- Processing mapping (-m)
- Turning off afinity (-a)
- Generate hosts and ranks file (-H)
- Limic (-L)
- OpenMP/Hybrid jobs
General use of mvp2run (-h, -v)
The first thing one will see if mvp2run is entered on the command-line on a front-end server is:
%> mvp2run a.out
mvp2run: not executing within a TORQUE environment.
This is because mvp2run can only be used within a job environment, with the one exception is that you can get the help summary shown above using the '-h' flag. All other mvp2run usage must be run within the batch system and should be added to your batch script.
For jobs which use all of the cores on a node, regardless of how many nodes or which compiler the executable was compiled with, the operation is the same:
%> mvp2run ./a.out <args> >&OUTThis will execute the program "a.out" with the arguments "args" using all cores/nodes requested by your batch script and stderr/stdout is redirected to the file "OUT".
A more verbose output will be generated if the '-v' flag is used including a summary of the nodes used and details about the parallel calculation. Regardless of whether '-v' is used, the final line of the mvp2run output is the actual command-line that is used to run the MPI program:
Wed Feb 14 2018 01:06:25 PM EST: /usr/local/amd64/seoul/intel/openmpi- 2.1.1-ib/bin/mpiexec -np 24 --bind-to socket /sciclone/home10/ewalter/a.out
This line is important since it shows what was actually executed on the cluster. The mvp2run command constructs this more complicated command-line out of its command-line arguments and specifics about the execution environment. Experts users can run this more complicated command-line directly in their batch script if desired. However, mvp2run provides some useful features that will be discussed below so this is strongly discouraged. Please email hpc-help@wm.edu for questions about this.
Passing variables to mvp2run (-e)
If there is an additional variable needed to be passed into the mvp2run execution environment, the flag '-e' can be used. This is done differently for the various MPI libraries:
MVAPICH2 - All variables that are passed to MVAPICH2 are in the form VAR=val. For instance, the MVAPICH2 variable, MV2_SHOW_ENV_INFO, can be set to 2 using:
mvp2run -v -e MV2_SHOW_ENV_INFO=2 a.out <args> >&OUT
Each VAR=val pair should be passed with an individual "-e" flag. A list of the variables available for MVAPICH2 are listed on (ref).
OpenMPI - For OpenMPI, some options are meant to be passed to the MPI environment, others are used to control the execution and are not sent to the environment. For instance, to pass an environmental variable to the MPI environment, the flag '-e' is still used, but the argument must be quoted and preceded with '-x' to signify it is meant for the execution environment:
mvp2run -v -e "-x OMP_DISPLAY_ENV=true" a.out <args> >&OUT
Options like "-report-bindings" are not environment variables and therefore do not need the '-x':
mvp2run -v -e "-report-bindings" a.out <args> >&OUT
- Unlike MVAPICH2, all variables and options can be put inside quotes after one '-e'. Users should consult the OpenMPI guide (ref) for more information about OpenMPI options.
IntelMPI - Like OpenMPI, IntelMPI has execution options and environmental variables. Unlike '-x', the environmental variables must be proceeded by '-genv'.
mvp2run -v -e "-genv OMP_DISPLAY_ENV=true" a.out <args> >&OUT
- Options like "-info" are not environment variables and therefore do not need the '-genv':
mvp2run -v -e "-info" a.out <args> >&OUT
Just as in OpenMPI, arguments to '-e' should be quoted and can be put together in oneargument to '-e'. However, some IntelMPI options use quotes so you may have to use single and double quotes to work out the logic.
Checking the load (-C, -X)
One feature that mvp2run provides is the ability to check the load on your allocated nodes to make sure they are idle. Both '-C' and '-X' take an argument which is the maximum acceptable load on all nodes involved in your job. This argument take a value between 0.0 (0%) and 1.0 (100%). The suggested value is 0.05 (5% load). The flag '-C' will write a warning on stdout:
Checking node cpu activity with threshold of 0.05 vx05: cpu load 0.1200 exceeds thresholdstating that a particular node has a load higher than the acceptable threshold (most likely due to a sick node or a previous job that wasn't killed properly). The flag '-X' does the same as '-C' but also terminates the job before starting. If you see either warning please send email to hpc-help@wm.edu as soon as possible so the node can be attended to.
Since these flags are to ensure that a node is idle they shouldn't be used when sharing nodes with other users since in this case the node should not be idle.
Process mapping (-m, -c)
There are instances where a user would like to use less than the full number of cores on a node or set of nodes. One common reason is that each core needs more memory than what it would have with every core used. Another example is in OpenMP/MPI hybrid jobs where you only need a few MPI processes and you want the rest to be used for OpenMP threads. Before this can be done, the cores must be mapped to particular nodes before execution.

Fig. 1. Two empty 4-core nodes.
In Fig. 1, we start with two idle nodes each with four processor cores. We have already found out that each process needs close to half of the memory available on each node. Therefore, we have decided to use all eight cores from both nodes, however, we are going to only use 2 cores per node. However, if we simple run on the first four cores available we will get the placement shown in Fig. 2.:

Fig. 2. 4 core job on 2 nodes using default mapping.
In this scenario, the first node is full and the second node is idle. This is why we must pass two additional flags, '-m' and '-c':
%> mvp2run -m blocked -c 4 ./a.out <args> >&OUT
Here, '-m' signals we want process mapping on and the type of process mapping is 'blocked'. The '-c' flag controls how many cores the program is executed on (rather than the default 8 cores). Fig. 3. shows the process placement given by this command line:

Fig. 3. 4 core job on 2 nodes using blocked mapping.
Fig. 3. shows the correct placement for only running two cores per node and the arrangement of the cores based on process id.
Alternatively, there may be code related reasons why you would want the processes arranged in a cyclic manner as shown in Fig. 4. which is obtained by using the cyclic mapping scheme:
%> mvp2run -m cyclic -c 4 ./a.out <args> >&OUT
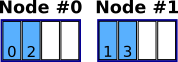
Fig. 4. 4 core job on 2 nodes using cyclic mapping.
Besides the blocked and cyclic schemes, the default scheme, 'vp' should never need to be explicitly selected.
Turning off process affinity (-a)
New information as of 7/26/18: We suggest that you run your application with the '-a' flag. Changes in the batch system have made the need for affinity less important and sometime it can slow down your job. Therefore, please consider at least checking if using the '-a' flag helps your application execution times.
Sometimes, especially in the case of OpenMP/MPI hybrid jobs, the best performance is obtained when process affinity (locking processes to a particular core or socket) is disabled. This is the default for jobs which share nodes with other jobs. By default, all MPI libraries enforce process affinity. MVAPICH2 and IntelMPI bind processes to cores by and OpenMPI binds processes to sockets (if the number of processes is >2 else it binds to cores). Using the '-a' flag, mvp2run will turn off all affinity options.
Using LIMIC2 (-L)
Limic2 is a linux kernel module developed by Konkuk University for MVAPICH2 to enable better shared memory performance within a node. It is only available for MVAPICH2 and is inviked via the '-L' flag for mvp2run.
Generate hosts and ranks file (-H)
Even though mvp2run should enable most all of the types of MPI calculations desired, it is conceivable that users may want to use some of the functionality of mvp2run (e.g. load checking, job and node information, process mapping), the '-H' flag can be used to generate the hosts file (used by all MPI libraries) and the ranks file (used by OpenMPI) so that is then written to your current working directory. These can then be passed to an actual MPI library execution program (i.e. mpiexec for OpenMPI) if desired. For example:
%> mvp2run -m blocked -c 4 -X 0.05 -H >&LOG %> mpiexec -np 4 -hostfile ./mvp2run.hosts -rankfile ./mvp2run.rank ./a.out <args> >&OUT
first we run mvp2run and asked for a blocked process mapping using 4 cores and we want to abort if the load is greater than 0.05. This will run and write 'mvp2run.hosts' and 'mvp2run.rank' file for use by the acutal MPI execution program.
For MVAPICH2 the hosts file and two variables are needed.
%> mvp2run -m blocked -c 4 -X 0.05 -H >&LOG %> mpirun_rsh -rsh -np 4 MV2_SMP_USE_LIMIC2=0 MV2_SMP_USE_CMA=0 -hostfile ./mvp2run.hosts ./a.out <args> >&OUT
MVAPICH2 uses mpirun_rsh to execute MPI programs and needs '-rsh' passed to it on SciClone and Chesapeake.
Same for IntelMPI although it is referred to as a machinefile
%> mvp2run -m blocked -c 4 -X 0.05 -H >&LOG %> mpiexec -np 4 -bootstrap rsh -machinefile ./mvp2run.hosts ./a.out <args> >&OUT
IntelMPI uses mpiexec just like OpenMPI, but needs '-bootstrap rsh' passed to it on SciClone and Chesapeake.
OpenMP/MPI hybrid examples
mvp2run can also run OpenMP/MPI hybrid jobs. This is when some subset of the allocated cores are used to run MPI processes and then these processes spawn a number of OpenMP threads. The total number of threads per MPI process X the number of MPI processes must equal the number of cores used in the job.
The exact options that one would use for a hybrid job depends both on the compiler and the MPI library. Here is one example using the Intel compiler and mvapich2 MPI. For all of these examples, the node specification is
-l nodes=2:vortex:ppn=12i.e. 2 vortex nodes and 24 total processors.
%> mvp2run -v -m cyclic -c 12 -a -e OMP_NUM_THREADS=2 -e KMP_AFFINTY=verbose,none ./a.out >& OUT
this command line uses the cyclic process mapping to launch 12 MPI processes on 2 vortex nodes with 6 MPI processes on each. Then, each process spawns 2 OpenMP threads for a total of 24 active cores. We also use the '-a' option to turn off the MPI library process affinity since it will hurt the OpenMP thread performance. The OMP_NUM_THREADS variable tells the executable how many OpenMP threads to launch and is passed as an environment variable on the command line. The KMP_AFFINITY variable controls the OpenMP threads affinity and should be investigated for your own code. A value of 'none' for KMP_AFFINITY may not be the best option for all OpenMP codes, but it is a good starting point. KMP_AFFINITY is only available for the Intel compiler.
Depending on your code, the blocked mapping might yield better results. Here we the same example for the Intel compiler using OpenMPI:
%> mvp2run -v -m blocked -c 12 -a -e "-x OMP_NUM_THREADS=2" -e "-x KMP_AFFINTY=verbose,none" ./a.out >& OUT
and the same for IntelMPI:
%> mvp2run -v -m blocked -c 12 -a -e "-genv OMP_NUM_THREADS=2" -e "-genv KMP_AFFINTY=verbose,none" ./a.out >& OUT
The difference between these three examples (besides the choice of process mapping) is the way variables are passed to the MPI library.
For the GNU compilers, there is no 'KMP_AFFINITY' variable since this is an Intel compiler specific option. GNU compilers use other other options for affinity. For example for the same hybrid job using the GNU compilers and MVAPICH2 MPI:
%> mvp2run -v -m cyclic -c 12 -a -e OMP_NUM_THREADS=2 -e OMP_PROC_BIND=false ./a.out >& OUT
OMP_PROC_BIND can be set to false to turn off affinity for the OpenMP threads. This is actually off by default unless other options are specified.
Here is the same for OpenMPI:
%> mvp2run -v -m cyclic -c 12 -a -e "-x OMP_NUM_THREADS=2 -x OMP_PROC_BIND=false" ./a.out >& OUT
and finally for IntelMPI:
%> mvp2run -v -m cyclic -c 12 -a -e "-genv OMP_NUM_THREADS=2" -e "-genv OMP_PROC_BIND=false" ./a.out >& OUT
For the PGI compiler, only mvapich2 and openmpi are supported. Many of the same OMP options used for GNU can be used for PGI. Please consult the PGI manual for more info.
